 December 1986
December 1986DOE/NBB-0081
Dist. Category UC-11
Prepared for
United States Department of Energy
December 1986
DOE/NBB-0081
Dist. Category UC-11
Prepared for
United States Department of Energy
Office of Energy Research
Office of Basic Energy Sciences
Carbon Dioxide Research Division
Washington, D.C. 20545
R.H. Gardner
Oak Ridge National Laboratory
Oak Ridge, TN
and
A. Brenkert
Science Applications International Corporation
Oak Ridge, TN
Under Contract No. DE-AC05-76OR0033
DISCLAIMER
This report was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference herein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof.
TABLE OF CONTENTS
Page Executive Summary . . . . . . . . . . . . . . . . . . . iii Preface . . . . . . . . . . . . . . . . . . . . . . . . v Acknowledgements . . . . . . . . . . . . . . . . . . . . vi Introduction . . . . . . . . . . . . . . . . . . . . . . 1 Background . . . . . . . . . . . . . . . . . . . . . . . 3 Modeling . . . . . . . . . . . . . . . . . . . . 3 Uncertainty . . . . . . . . . . . . . . . . . . 7 Uncertainty Analysis Techniques . . . . . . . . . . . . 8 The Model . . . . . . . . . . . . . . . . . . . . . . . 14 Model Overview . . . . . . . . . . . . . . . . . 14 Energy Demand . . . . . . . . . . . . . . . . . 16 Energy Supply . . . . . . . . . . . . . . . . . 18 Energy Balance . . . . . . . . . . . . . . . . . 19 CO2 Release . . . . . . . . . . . . . . . . . . 20 The Data Base . . . . . . . . . . . . . . . . . . . . . 23 Determination of Input Data Values . . . . . . . 26 Summary of Distribution of Input Assumptions . . 28 Results . . . . . . . . . . . . . . . . . . . . . . . . 28 The Monte Carlo Simulation Exercise . . . . . . 31 Uncertainty in Future Carbon Emissions, 1975-2075 32 A Comparison of Emissions Projections . . . . . 41 A Comparison of Projected Emission Variability to Historical Variability . . . . . . . 46 CO2 Trajectories . . . . . . . . . . . . . . . . 50 Importance of Input Assumptions . . . . . . . . 59 Analysis of Energy Results . . . . . . . . . . 75 Conclusions . . . . . . . . . . . . . . . . . . . . . . 83 Notes . . . . . . . . . . . . . . . . . . . . . . . . . 87 References . . . . . . . . . . . . . . . . . . . . . . . 91 Appendix A, Monte Carlo Data Set . . . . . . . . . . . . A-1 Appendix B, The IEA/ORAU Long-Term Global Energy-C02 Model Version A.84--Model Improvements . . . . . B-1 Appendix C, Variable Definitions and Cross Correlations. C-1 Appendix D, Detailed Results . . . . . . . . . . . . . . D-1 Appendix E, Monte Carlo Techniques . . . . . . . . . . . E-1 Appendix F, The IEA/ORAU Long-Term Global Energy Economic Model Software . . . . . . . . . . . . F-1
EXECUTIVE SUMMARY
Summary
This report documents the results of work with the IEA/ORAU Long-Term Global Energy-CO2 model to analyze model predictions of future global carbon emissions form fossil fuel use and the uncertainty surrounding such forecasts. This project was jointly conducted by the Institute for Energy Analysis (IEA/ORAU) and the Oak Ridge National Laboratory (ORNL) for the U.S. Department of Energy.(a)
Approach
The methodology utilized state-of-the-art techniques of uncertainty analysis along with review and revision of the IEA/ORAU model structure (documented fully in Appendix B), and review and description of uncertainty surrounding model assumptions and parameters (documented fully in Appendix A) to explore uncertainty in fossil fuel CO2 emissions over the period 1975-2075. Possible interrelationships among assumptions and parameters, and their effects on overall forecast uncertainty are explored.
The fact that uncertainty is described should not mislead readers into concluding that whereas we do not know the future with certainty, we do know the uncertainty about the future with certainty. An uncertainty analysis does not change the fundamental modeling relationship. Model assumptions (description of uncertainty about model assumptions) interact with a model structure (assumed known by hypothesis) to produce a scenario (description of scenario uncertainty).
Results
The major findings include:
PREFACE
This report documents a research project undertaken jointly by the Institute for Energy Analysis, Oak Ridge Associated Universities, and the Oak Ridge National Laboratory for the U.S. Department of Energy, Carbon Dioxide Research Program. The objective of this research project was to explore uncertainty in future fossil fuel related CO2 emissions over a century time horizon (1975-2075). In support of that objective a data base was developed, the IEA/ORAU global energy-CO2 emissions model was modified, model documentation was revised, the new model was transferred to CDIC and uncertainty analysis was conducted. This project builds on a substantial base of preceding work including Edmonds et al. (1984) and Edmonds and Reilly (1985).
The report is structured in three levels, an executive summary, accessible to the general reader and intended to convey only the most general highlights of the study, the main body of the report, also accessible to the general reader and intended to describe in detail, background approach, and results of the study, and a set of appendices, intended for a technical audience interested in the fullest technical description of the model, data base, methods, and results.
ACKNOWLEDGEMENTS
The authors wish to express their appreciation to Fred Koomanoff, Program Director at the Carbon Dioxide Research Division of the U.S. Department of Energy and to Roger Dahlman for their support. In addition we appreciate the help of Marvin Miller and Irving Mintzer who reviewed this document. Special thanks go to John Trabalka whose unflagging support of their undertaking helped make it possible. Finally, we are indebted to Fay Kidd for typing and editing numerous drafts which we are Indebted to many for helping us craft this document, the final responsibility for its accuracy and usefulness resides solely with the authors. This publication is based on work contracted for by the U.S. Department of Energy, Office of Energy Research, Carbon Dioxide Research Division, under Contract No. DE-AC05-76OR0033 with Oak Ridge Associated Universities, and at the Pacific Northwest Laboratory under contract No. DE-AC06-76RLD, and with Oak Ridge National Laboratory under contract No. DE-AC05-84OR21400.
UNCERTAINTY IN FUTURE GLOBAL ENERGY USE AND FOSSIL FUEL CO2 EMISSIONS
INTRODUCTION
This report deals with the long-term future of the world's energy system and its associated emissions of carbon dioxide (CO2) a radiatively active atmospheric constituent. The time and geographic scales are large, 100 years into the future and the entire globe. Such scales are made necessary by the nature of the problem. Emissions of CO2 mix rapidly throughout the entire global atmosphere. Its long resident time implies the accumulation of carbon concentrations and it is the prospect of large scale CO2 accumulation over the course of this and the next generation that raises the spectre of major changes in the earth's radiative energy balances and possible climatic and geophysical consequences.
The long-term future of the global energy system is unknowable and hence unpredictable. And yet to affect the future we must look forward into it. In fact, part of the future's uncertainty stems directly from the fact that alternative human activities have vastly different consequences. This desire to look forward and inability to predict the future leaves us walking a very narrow intellectual tightrope.
In the work that follows we will attempt to structure the interactions among various relevant human activities, assess uncertainty about the future course of such events and using recently developed techniques of quantitative analysis describe the consequent uncertainty surrounding future emissions of CO2.
At first blush the jump from predictive forecasting to quantitative uncertainty analysis may appear to solve the problem of forecasting the future. It may appear that while we cannot know the future, we can predict the uncertainty distribution surrounding the future. But this is in fact not the case. The crucial relationship between output (in this case future CO2 emissions); model (the description of how human activities interact with each other to determine CO2 emissions); and inputs (assumptions about relevant human activities) has not been altered. The uncertainty analysis merely translates uncertainty about key assumptions through a consistent, logical structure describing their interactions into an implied uncertainty about CO2 emissions
Thus, just as the accuracy of a predictive forecast depends completely on the accuracy of both its assumptions and model, the accuracy of an uncertainty analysis depends completely on the accuracy of the distribution of assumptions and the model. The quality of analysis that comes out still depends completely on the quality of the analysis going in.
The question then arises as to why bother to go to all the trouble of an uncertainty analysis in the first place. The answer to that is that a great deal can be learned. An uncertainty analysis not only works out the consequences of what are held to be "likely" assumptions but also the consequences of unlikely assumptions and combinations of events, some of which are likely and some of which are unlikely. By systematically exercising a model in this way, we were able to test the sensitivity of forecasts to assumptions, explore the behavior of the model under extreme and what are currently believed to be unlikely assumptions (though
assumptions which future events may cast in a different light), assess the relative importance of alternative assumptions and explicitly rephrase the question of future CO2 emissions in terms of a best guess with confidence intervals.
In the remainder of the paper we will explore the brief history of CO2 emissions forecasting and the way in which uncertainty has been addressed, describe our approach, including the Monte Carlo uncertainty analysis, the model, and data base development, present the results of our analysis, including a description of future CO2 emissions uncertainty, and an analysis of parameter contributions to forecast variation, and offer a comparison of this research to other research, in particular the uncertainty analysis conducted by Nordhaus and Yohe (1983)
BACKGROUND
The relatively brief history of fossil fuel CO2 emissions forecasting has seen rapid evolution in both the way future emissions are forecast (modeling) and the way in which uncertainty is handled1.
Modeling
Early studies forecast fossil fuel CO2 emissions by extrapolating a time-trend of energy use and CO2 emissions from the post-World War II record, for example JASON (1979) and Bacastow and Keeling (1981). The resulting analysis led researchers to predict that atmospheric concentrations of CO2 would reach 600 ppm, roughly double the pre-industrial level, early in the next century.
Other researchers fixed a pool of carbon which they felt would be vented and then distributed emissions through time with a variety of the logistics curve specifications, for example see Keeling and Bacastow (1977) and Rotty (1979). This model led researchers to expect CO2 "doubling" to occur nearer the middle of the next century than the beginning.
Both approaches have come under heavy criticism, Ausubel and Nordhaus (1983) and Edmonds and Reilly (in press). Neither early approach establishes a meaningful link between human activity and CO2 emissions. The simple time-trend extrapolation implies no significant changes in any underlying human activities which affect CO2 emissions. The logistics curve models are time-driven models constrained by a pool of carbon to be dispensed over time. The problem with this structure is that the analyst must know the size of the pool of carbon vented over all time as well as the time profile of its dispersion. Since the total carbon resource base is too large to provide any meaningful bound on its own, the researcher must determine this crucial parameter exogenously. And it is this exogenous, usually undocumented, analysis, which must implicitly or explicitly weigh the various influences of such human activities as technological progress, economic growth and development, energy price paths, population growth, the energy resource base and its gradations, and the relative cost of alternative fossil and non-fossil energy production technologies, in the context of the human decisionmaking process. As a consequence, researchers and policymakers are left painfully unable to ask the "what if" questions that arise naturally.
Other researchers have used techniques which deal with these issues more directly. This includes both feasibility studies and energy-economy
studies. Feasibility studies ask the question: Could the world achieve a low energy-low CO2 emissions future? Reports by Lovins et al. (1981), Perry et al. (1982), and Williams et al. (1984), among others, have explored explicitly the technical feasibility of such futures.
The mainstream of CO2 emissions analysis has adopted energy-economic based analysis. See, for example, Perry and Lansberg (1977), Nordhaus (1979), Allen et al. (1981), Haefele (1981), Edmonds and Reilly (1983c), and Nordhaus and Yohe (1983).2 The structures of these models vary greatly, but all are used as behavioral forecast tools.3
Figure 1 depicts the history of best guesses over the last decade. The best guess of studies have been classified into three groups corresponding to the analytical methodology: time-trend/logistics curve studies, energy-economic studies, and feasibility studies. To some degree this classification scheme is arbitrary. Nevertheless taken as a group, the feasibility studies show a markedly different history than the time-trend/logistics curve and the energy-economic studies. The latter group may be taken to represent the mainstream of CO2 emissions forecast thought. Over time the area of debate shifted markedly downward. Prior to 1981 the rate of CO2 emissions was expected to grow at an annual rate of between two and four percent per year between 1975 and 2050. After 1983 the range shifted downward to between zero and two percent per year. It is interesting to observe that this downward drift in the area of debate in best guess forecasts does not seem to involve the shift from logistics curves to energy-economic studies. Rather this shift seems to represent a general revision in thinking shared by forecasters using both types of
model. Perry and Lansburg (1977), for example, fit nicely within the spectrum of logistics curve forecasts published during that period in time.
Feasibility studies are another genre entirely. Their focus on possible low energy-low CO2 emissions futures led them to publish very different emissions forecasts in the pre-1981 period. But the most recent study, Williams et al. (1984), indicates a significant upward revision in CO2 emissions forecasts.
This seeming consensus of opinion needs to be examined in light of two other factors, uncertainty and the general trend toward forecast clustering
Uncertainty
Uncertainty is a major feature on the landscape of emissions forecasting. It is more prominent here than in most analyses because of the extremely long time horizons involved in the exercise and the consequent expectation that key variables will take on values well outside of the historical experience.
Before 1983 published studies generally took three alternative approaches. Some forecast a single best guess emissions scenario, e.g., Perry and Lansburg (1977), JASON (1979), Nordhaus (1979), Allen et al. (1981), Lovins (1981), and Edmonds and Reilly (1983c). Others forecast alternative scenarios which were deemed reasonably likely, but for which no explicit probability assessment was made, e.g., Haefele (1981), and Seidel and Keyes (1983). Finally some attempted to construct bounds on possible future emissions, e.g., Rotty and Marland (1980), Siegenthaler and Oeschger (1978), and Niehaus and Williams (1979).
The quest to physically bound the emissions of CO2 proved to be impossible. Terrestrial deposits of carbon are too large to prevent a major buildup of CO2 emissions. Feasibility studies have called into question whether or not there are any meaningful lower bounds on CO2 emissions. Similarly the lack of explicit representation of forecast uncertainty has led to a frustration with best guess and multiple scenario analysis.
In 1983 Nordhaus and Yohe published the first uncertainty analysis. This analysis utilized Monte Carlo techniques which they termed "probabilistic forecast analysis." A global energy-economic model which employed nine forecast parameters served as the organizational framework. A review of the literature was conducted to assess uncertainty for each parameter. A series of Monte Carlo forecasts were generated by repeated random drawings of values for each variable. As a consequence, Nordhaus and Yohe became the first researchers to explicitly describe future CO2 emissions in terms of uncertainty. This study is only the second such analysis.
UNCERTAINTY ANALYSIS TECHNIQUES
The conduct of an uncertainty analysis allows the researcher to make an explicit probabilistic description of alternative future paths of CO2 emissions, assess the relative importance of individual assumptions (parameters) in explaining forecast variance, and explore the consequences of extra model interrelationships among variables.
The basic approach of Monte Carlo uncertainty analysis is to produce a large number of scenarios, each scenario being the result of a set of values of input parameters selected from distributions representing
uncertainty derived individually for each parameter. Assuming that the model accurately characterizes the structure of the system being modeled and that the distributions characterizing uncertainty in input assumptions are correct, the scenarios generated by the process represent a random sample from the population of possible future CO2 emissions paths.
The application of these general procedures to the IEA/ORAU model is illustrated in Figure 2. The procedure begins with the development of uncertainty distributions. The IEA/ORAU model has 79 input variables.4 (See Table 1.) Four-hundred input scenarios are generated from these 79 uncertainty distributions by a systematic procedure called, Latin Hypercube sampling (see Appendix E for a detailed discussion of procedures). Each of the 400 scenarios contain quantitative values for each of the 79 input parameters. Each of the 400 scenarios is different. Each data set is fed into the model one at a time. For each data set (scenario) the model projects associated energy and CO2 omissions outputs. Ninety-five output variables are tracked (see Table 2). The 400 scenario values for each model output value are then collected to reveal the uncertainty distribution for each of the 95 output variables. (See RESULTS and appendices C and D.) In addition an analysis can be conducted to assess the relative contribution of each of the 79 input variables to the overall uncertainty of any output variable (See RESULTS.)
It should be repeated here that while the techniques employed in the conduct of an uncertainty analysis are powerful and useful, they do not constitute a crystal ball. Each of the hundreds of scenarios generated simply works out the consequences of a set of assumptions systematically generated from a distribution supplied by the researchers to a formal model. The model (like all models) is only as good as the analysis which
built it. The distribution for each input assumptions are only as good as the assessments that created them.
THE MODEL
The IEA/ORAU Long-Term Global Energy Economic Model was modified for the conduct of this analysis. The original version of the model is documented in Edmonds and Reilly (1984). It was developed under contract to the U.S. Department of Energy for the Carbon Dioxide Research Division, the sponsoring agency for this research. It has been adopted for CO2 emissions research by several other institutions as well, including the U.S. Environmental Protection Agency, the Massachusetts Institute of Technology, the Electric Power Research Institute, the Gas Research Institute, and is available from the Carbon Dioxide Information Center at the Oak Ridge National Laboratory, which has distributed it to thirteen researchers in five countries.
Model Overview
The model can be thought of as consisting of four parts: supply, demand, energy balance, and CO2 emissions. The first two modules determine the supply of and demand for each of six major primary energy categories (see Table 3) in each of nine global regions (see Figure 3). The energy balance module ensures model equilibrium in each global fuel market. (Primary electricity is assumed to be untraded, thus supply and demand balance in each region.) The CO2 emissions module is a post-processor. Substantial modifications have been made to the supply, demand, and energy balance modules. These are documented in Appendix B. The model can be used to develop projections for any desired year, but four benchmark years were chosen for scenarios--2000, 2025, 2050, and 2075.
Energy Demand
Energy demand for each of the six major fuel types is developed for each of the nine regions separately. Five major exogenous inputs determine energy demand: population, labor productivity, energy efficiency improvement, energy prices, and energy taxes and tariffs.
The model calculates base GNP directly as a product of labor force and labor productivity. An estimate of base GNP for each region is used both as a proxy for the overall level of economic activity and as an index of income. The base GNP is, in turn, modified within the model to be consistent with energy-economy interactions. The GNP feedback elasticity is regional, allowing the model to distinguish energy supply dominant regions, such as the Mideast where energy prices and GNP are positively related, from the rest of the world where the relationship is inverse.
The exogenous end-use energy efficiency improvement parameter is a time-dependent index of energy productivity. It measures the annual rate of growth of energy productivity which would go on independent of such other factors as energy prices and real incomes. In the past, technological progress and other nonprice factors have had an important influence on energy use in the manufacturing sector of advanced economies. The inclusion of an exogenous end-use energy efficiency improvement parameter allows scenarios to be developed that incorporate either continued improvements or technological stagnation assumptions as an integral part of scenarios.
The final major energy factor influencing demand is energy prices. Each region has a unique set of energy prices derived from world prices (determined in the energy balance component of the model) and region-specific taxes and tariffs. The model can be modified to accommodate nontrading regions for any fuel or set of fuels. It is assumed that no trade is carried on between regions in solar, nuclear, or hydroelectric power, but all regions trade fossil fuels.
The energy-demand module performs two functions: it establishes the demand for energy and its services and it maintains a set of energy flow accounts for each region. Oil and gas are transformed into secondary liquids and gases used either directly in end-use sectors or indirectly as electricity. The solid primary fuels, coal and biomass, can either be used in their solid forms or may be transformed into secondary liquids and gases or electricity. Hydro, nuclear, and solar electric are accounted directly as electricity. Nonelectric solar is included with conservation technologies as a reduction in the demand for marketed fuels.
The four secondary fuels are consumed to produce energy services. In the three Organization for Economic Co-Operation and Development (OECD) regions (Regions 1, 2, and 3 in Figure 3), energy is consumed by three end-use sectors: residential/commercial, industrial and transport. In the remaining regions, final energy is consumed by a single aggregate sector.
The demand for energy services in each region's end-use sector(s) is determined by the cost of providing these services and by the levels of income and population. The mix of secondary fuels used to provide these services is determined by the relative costs of providing these services using each alternative fuel. The demand for fuels to provide electric power is then determined by the relative costs of production, as is the share of oil and gas transformed from coal and biomass.
Energy Supply
Energy supply is disaggregated into two categories, renewable and non-renewable.5 The categorization is given in Table 4.
Energy supply from all fossil fuels is related directly to the resource base by grade, the cost of production (both technical and environmental) and to the historical production capacity. The introduction of a graded resource base for fossil fuel (and nuclear) supply allows the model to explicitly test the importance of fossil fuel resource constraints as well as to represent fuels such as shale oil in which only small amounts are likely available at low costs but for which large amounts are potentially available at high cost.
Note here that nuclear is treated in the same category as fossil fuels. Nuclear power is constrained by a resource base as long as light-water reactors are the dominant producers of power. Breeder reactors, by producing more fuel than they consume are modeled as an essentially unlimited source of fuel available at higher cost.
A rate of technological change is now introduced on the supply side. This rate varies by fuel and is expected to be both higher and less certain for emerging technologies.
Energy Balance
The supply and demand modules each generate energy supply and demand estimates based on exogenous input assumptions and energy prices. If energy supply and demand match when summed across all trading regions in each group for each fuel, then the global energy system balances. Such a result is unlikely at any arbitrary set of energy prices. The energy balance component of the model is a set of rules for choosing energy prices which, on successive attempts, brings supply and demand nearer a system-wide balance. Successive energy price vectors are chosen until energy
markets balance within a prespecified bound. Figure 4 displays the interactions necessary to achieve a global energy balance.
CO2 Release
Given the solution from the energy balance component of the model, the calculation of CO2 emissions rates is conceptually straightforward. The problem merely requires the application of appropriate carbon coefficients (carbon release per unit of energy) at the points in the energy flow where carbon is released. Carbon release is associated with the consumption of oil, gas, and coal. Significant carbon release is also associated with production of shale oil from carbonate rock. A direct zero carbon release coefficient is implicitly assigned to nuclear, hydro, and solar power and to conservation. Actual calculation of CO2 emissions is made somewhat more complex than indicated by the conceptual simplicity, but primarily because of the need to appropriately account for flows of carbon that are not oxidized (see Figure 5).
A considerable literature exists concerning appropriate values for CO2 coefficients. Those in Table 5 were calculated at IEA/ORAU by Gregg Marland and Ralph Rotty. The coefficients are representative of average global fuel of a given type and are consistent with the model's CO2 accounting conventions as indicated by Figure 5.
THE DATA BASE
The IEA/ORAU long-term global energy-economic model, Version A84, uses a numeric data base which is benchmarked to 1975 United Nations energy statistics. The data set contains 2126 elements grouped under 50 parameter names (see Table 6). This data set is displayed in Appendix F, lines 6165-7031. Of the 2126 elements 381 are used exclusively to benchmark the model and 360 are available to examine energy trade and tax policies. The remaining 1385 data elements are forecast variables. Of these 70 are related solely to calculating the rate of CO2 emissions. Of the 1315 energy forecast data elements 649 were involved in the uncertainty analysis.
A total of 666 energy forecast data elements were omitted from the analysis. Data elements were omitted to reduce the computational burden. Elements were selected because they were either uninfluential in the determination of energy balances (e.g., TRI), an integral part of model structure (e.g., BSUILM), or a variable whose uncertainty could be directly captured by varying a partner variable (e.g., RIGISL was varied but CIGIS was not). To reduce the computational burden still further, the 649 data elements were tied to 79 "driving" variables via a set of aggregation procedures. Aggregations were made along natural lines (see Table 1). For example uncertainty surrounding the global hydroelectric resource base was examined but this one Monte Carlo variable aggregated resources across nine global regions.
Determination of Input Data Values
Quantitative values, for all 1385 forecast data elements were contained in the data base for each scenario run. For the 736 energy forecast data elements that were not varied, median forecast values were used. These values were taken from the benchmark data sets of model version B82. Information used to develop the median values for data is contained in Edmonds and Reilly (1985), but to date no element-by-element description of the derivation of quantitative values has been published.
The derivation of quantitative values for parameters used in the Monte Carlo analysis is formally documented. See Appendix A. The derivation of uncertainty distributions for each parameter is also documented there. The derivation of Monte Carlo parameter distributions from historical data, literature, and other information is summarized in a set of "data sheets."6
The data sheets provide a standard format for each "input assumption" (e.g., 4 Monte Carlo parameters or variables are associated with coal supply; coal supply is considered one input assumption). Each data sheet identifies the following: the input assumption (e.g., coal supply), the number of Monte Carlo variables that help to determine coal supply, the specific variables involved (as listed in the computer code), a discussion of the data format for the Monte Carlo analysis, a discussion of how the Monte Carlo data is integrated with the model specification, a discussion of potential correlation with other variables in the model, relevant bibliographic sources, a list of experts in the area, the specific distribution for each parameter, the specific rule for disaggregation to model region (as necessary), and finally a worksheet (as necessary).
The topical headings are, for the most part, self explanatory and their purpose obvious. We offer further explanation for the following:
The list of experts is generally a partial list compiled as a by-product of the literature review and other attempts to glean available information. It is included to provide for possible individual or panel/workshop expert elicitation if such exercises are judged to be useful in light of the results derived from the current Monte Carlo exercise. Inclusion on the list does not necessarily indicate that the expert was contacted for the data compilation reported here.
Specific distributions are given for each parameter. In general, we give a value for the 3, 16, 50, 84, and 97 percentiles. Some of these points were dropped in cases where it was felt that available evidence allowed for no more resolution than, for example, to assume a uniform distribution between extremes. The distributions are assumed continuous and linear between values. This allows for as much resolution as we feel can be ascertained from available information while also allowing for more flexibility than would be obtained by assuming all distributions to be normal, uniform or some other functional distribution.
The worksheet contains a complete documentation of the specific sources used in deriving distributions and any intermediate calculations, assumptions, and considerations. In cases where there is little or no hard evidence on the parameter the worksheet is noticeably thinner. In these cases we have made the distribution correspondingly broader to reflect obvious ignorance concerning values for the parameters. If the Monte Carlo analysis shows these parameters to be unimportant, even though highly uncertain, they can be safely ignored. If, on the other hand, they are shown to be important sources of uncertainty in carbon emissions, increased effort at understanding the parameter (and processes involved) is indicated.
Summary of Distribution of Input Assumptions
Table 7 provides a summary of the distribution assigned to Monte Carlo parameters. Refer to Table 1 and Appendix C for an explanation of the relationship between Monte Carlo Parameters (PARMs) and specific model parameters and of the form the parameters take (e.g., as a percentage growth, level, or index). The distribution characteristics given in Table 7 are based on the sample data used to produce the Monte Carlo distributions. The reader is cautioned in interpreting this data. The distributions characterized by these summary statistics are not simple functional distributions (e.g., normal or uniform) and are not symmetric. Thus, the means are not identical to the medians and usually are greater than the medians.
RESULTS
Results of the study fall into two general categories: (1) descriptions of the distributions of variables predicted by the model, the primary variable of interest being future carbon emissions; and (2) assessment of the relative importance of input assumptions in determining the results which provides a useful summary of the model structure. The following sections include a discussion of these two types of results organized around the following major headings: Uncertainty in Future Carbon Emissions, 1975-2075, A Comparison of Emissions Projections, A Comparison of Projected Emissions Variability to Historical Variability, CO2 Trajectories, Importance of Input Assumptions, and Analysis of Energy Results.
The Monte Carlo Simulation Exercise
Ninety-five of output values are selected as likely to provide interesting results in the Monte Carlo analysis. The selected variables are given in Table 2. Because of the need to limit the amount of output saved from each of the numerous runs, the focus is on global aggregates. For solar and nuclear electricity costs, U.S. figures are given as indicative of world prices since world trade in electricity does not exist in the model.
Two separate Monte Carlo exercises were conducted.7 Results from both are reported. The first exercise is based on the 79 uncertainty distributions described in Appendix A. Here 42 of the 79 variables are assumed to be distributed independently of each other while the remaining 37 Monte Carlo parameters are deterministically linked to the other 42.8 The variation in model outputs associated with this underlying description of input uncertainty is hereafter referred to as the "zero correlation case."
The second exercise was designed to test the effects of possible extra model interactions among variables. For example, a significant body of literature shows that knowledge (technological progress) is a driving force in economic growth, that knowledge and capital flow freely across borders, and that the existence of trade in goods all serve to link economic growth among countries and regions. Thus, it might seem more likely that the developing countries would grow rapidly in the future if growth in the developed countries is rapid.
Similarly one might argue that advances in basic knowledge lead to across-the-board improvements. Therefore, if labor productivity was likely to advance rapidly due to technological advance then energy productivity
might also advance rapidly. Table 8 summarizes the correlations assumed with more detail given in Appendix A. Additional nonzero correlations exist in the final data set due to the fact that the primary correlations specified in Table 8 imply additional relationships among parameters. For example, a positive correlation in regional income elasticities between the OECD (PARM 7) and developing regions (PARM 9) and the OECD (PARM 7) and EUSSR region (PARM 8) means that PARM 8 and PARM 9 must also be correlated.
This second exercise is hereafter referred to as the "non-zero correlation case."
Uncertainty In Future Carbon Emissions, 1975-2075
While we have made this point several other times in this paper, it is sufficiently important that it bears repeating. The accuracy and relevance of the forecast CO2 emissions and associated uncertainty distributions depend completely on the uncertainty distribution for model inputs and on the model structure. If either the uncertainty distribution for inputs or the model are misspecified, then the forecast emissions and their associated uncertainties will be incorrect as well. The results that follow are therefore only as good as the analysis that generated them.
Figure 6 provides a plot of key percentile values of the distributions of predicted carbon emissions to 2075. Mean and median rates of emissions are translated into rates of growth in Table 9.
We note immediately that the emissions distribution of forecast is non-normal. Median values are significantly lower than mean values for both the correlated and uncorrelated cases. Median forecasts (half the cases lie above and half below the median value) are consistent with rates
of growth of CO2 emissions below 1 percent per year. This is lower than that found in most other forecast studies (though feasibility studies have produced lower and even negative rates of growth). The mean (average) forecast for both zero and non-zero correlation cases lie between 1.5 and 2.0 percent per year rate of growth of emissions and are closer to results obtained by other studies.
A record observation is the tendency for the rate of growth of CO2 emissions to be higher in the period 2000-2025 than in the period 1975-2000. The median, non-zero correlation case being an exception. This tendency for an acceleration in the rate of growth of CO2 emissions in the 2000-2025 period is mirrored in the base case BC 84. The base case is the scenario in which median values for all inputs are run.
In BC 84 the spurt in the rate of growth of emissions results from an accelerated rate of growth in natural gas production and the emergence of a synthetic fuels industry which more than offset the declining rate of growth of conventional oil, nuclear power, hydroelectric power and solar electric power.
The dashed lines in Figure 6 give the corresponding percentile values for the run where nonzero correlations among PARMS are assumed. The graph suggests what appears to be a fairly clear narrowing of the distribution. It also shows a significant reduction in median values. All of the assumed correlations would tend to narrow the distribution with the exception of the correlation among regional productivity growth rates. Since productivity growth rates are such an important factor in explaining the distribution, it is interesting to note that the combination of other factors tends to outweigh this effect.
Table 10 provides additional statistics of the frequency distributions of carbon emissions. Note that a frequently used measure of variability, the coefficient of variation, is larger in the nonzero correlation case. Thus, the conclusion that the frequency distribution of carbon emissions is narrower under the assumed set of cross-correlations is dependent on the particular measure of variability chosen.
Figure 7 gives considerably more detail on the distribution of emissions for the years 2000-2075. As can be seen, one-fourth of the cases show a roughly constant or lower carbon emissions than current levels through 2075--the consequence of a rough balance in two opposing trends: a gradual increase in the median value and a gradual spread in the overall distribution. This conclusion contrasts with Nordhaus and Yohe's (p. 94) results. They show 25 percent of their cases falling below four gigatons in 2000, whereas we show roughly 15 percent of our cases below 4 gigatons in 2000. However, beyond 2000 the Nordhaus/Yohe results show less than 5 percent of the cases below 5 gigatons (approximately current emissions) with the 5 percentile level of emissions increasing to 7.2 gigatons per year by 2100.
If one wishes to interpret the modeling results as making predictive statements about the future, our results suggest a significant chance that future emissions will fall from and stay below current levels of emissions whereas the Nordhaus/Yohe results suggest a near inevitable increase in the rate of emissions over time. Results from the zero correlation case also show a somewhat greater chance of higher levels of emissions particularly over the next 25 years. Nordhaus and Yohe (p. 94) suggest a one in four
chance that CO2 concentration will double before 2050 based on a 75th percentile emissions rate of 7 gigatons in 2000, 13 in 2025, and 17 in 2050. Our corresponding 75th percentile rates are 8, 15, and 24. Under the set of assumed correlations our 75th percentile values differ from the Nordhaus and Yohe values considerably less: our values are 8, 13, and 19. These differing results can be traced to our finding of less certainty about the future as indicated by the coefficient of variation and combined with our higher median in the year 2000 but a lower median beyond 2000 (see Table 11).
A Comparison of Emissions Projections
The results of the Monte Carlo exercise can be compared to other emissions projections efforts and techniques. One interesting comparison is the median output versus the output when median values of inputs are used. One justification for Monte Carlo analysis is that it improves on projections by recognizing the impact of nonlinearities in an uncertain world. For example it is well known that E(f(X)) = f(E(X)) only if f is a linear function of X. This means that if one carefully determines average values for all input assumptions, enters them into a model, and runs it, there is no reason to believe that the results are the same as the average over all input combinations, even assuming the model to be structurally correct. In addition, there is no reason to believe that running the model with most likely values for all inputs will yield the most likely output.
Model nonlinearity is not the only factor leading to divergence in mean and median scenarios and scenarios with either mean or median input values. Asymmetry of input probability density functions also plays a role. This impact of nonlinearity can be seen by direct comparison, (Figure 8). Emissions in the median value inputs case reach almost 21 gigatonnes by 2075. In contrast, the Monte Carlo case with nonzero correlation shows emissions of only 8.5 gigatonnes or just over 40 percent of the median inputs case. The Monte Carlo case with zero correlation shows a median output of 12.6 gigatonnes in 2075. Thus, these various techniques using the same model and same data sets yield significantly different results. In contrast, both mean emissions follow similar trajectories to the scenario with median input values.
It is also possible to compare results to other studies. Figure 9a compares 95th, 50th, and 5th percentile values of this study to those of Nordhaus and Yohe (1983). This comparison is of particular interest since the general projection technique used is the same but the model and data were independently developed. The Nordhaus and Yohe (N-Y) study shows a considerably narrower range of uncertainty beyond 2000 and particularly low emissions in the year 2000. Some of the sources of these differences have been discussed earlier.
Figure 9b compares the 95th, 50th, and 5th percentile values of this study to Edmonds et al. (1984). The comparison is of interest in documenting the impact on results of changing the structure of the IEA/ORAU model and the impact of using Monte Carlo techniques. A few observations can be made. First, comparing the ER-1984 MID (Case B) scenario (Figure 9b) to the median input value case (Figure 8) shows very little difference as a result of the structural changes in the model. This might be expected given the nature of many of the changes; i.e., they were designed to simplify data entry or internalize relationships which formerly required user interaction. However, some of the changes are significant enough to illustrate problems in comparing model structures (e.g., the graded resource concept versus the fixed resource concept for oil and gas are so dissimilar that it is impossible to fully standardize resource data between the two model versions). Thus, changes in results may be due partly to structure and partly to data. It is reassuring that results are very similar between the runs (7.2, 10.3, 14.5, and 18.8 GT from 2000-2075 in the ER-1984 study and 6.9, 10.3, 14, and 20.7 in the comparable run in the current study).
Also of interest is different characterizations of uncertainty yielded by the two exercises. Several points emerge: first, the spread of the ER-1984 study in the year 2000 is much narrower than the spread yielded by the Monte Carlo analysis. If one believes that the Monte Carlo results are indicative of existing uncertainty one must conclude that the ER-1984 scenarios are three slightly different mid cases for 2000. This may be directly attributable to the fact that ER-1984 held oil and gas resources constant; this might be expected to lead to a narrow spread in earlier years with little impact in later years since under nearly any plausible resources assumptions conventional oil and gas have dwindled significantly by 2025. In addition labor productivity is not varied nearly as much in ER-1984 as in the Monte Carlo analysis.
A second point which emerges is how relatively high the ER-1984 LOW (Case C) scenario is compared to the Monte Carlo results. It is just slightly lower than the Monte Carlo 50th percentile value with nonzero correlation. Carbon emissions are 6.8 gigatonnes in 2075 in the ER-1984 LOW (Case C) scenario compared to 1.1 and 1.8 gigatonnes in the 5th percentile values of the Monte Carlo analysis.
A third point is the relatively high values for the ER-1984 MID (Case B) case. This appears attributable to the interaction of uncertainty and nonlinearities as shown in Figure 8.
Finally, the near identical 2075 value in the ER-1984 HIGH (Case A) and for the Monte Carlo 95th percentile is an interesting coincidence. A comparison between the HIGH (Case A) and 95th percentile values raises a point of interpretation; specifically, the path portrayed by the connection of similar percentile values over time need not represent a realistic
timepath. The specific pattern of the 95th percentile values is a combination of scenarios which peak at high values in 2025 or 2050 and decline and scenarios which may be relatively low in those years but continue increasing rapidly through 2075.
A Comparison of Projected Emission Variability to Historical Variability
As an attempt to validate a similar projection effort, Nordhaus and Yohe compare historical variability in CO2 emissions based on regression trend analysis with projected variability based on their model. We can compare our results directly to the Nordhaus and Yohe model projections and their historical variability estimates. Table 11 is taken directly from their study (p. 144) with our comparable model projections added in the last two columns. The first added column is based on results when no correlation among inputs are assumed. The second column are results with the assumed set of correlations (from Table 4).
Nordhaus and Yohe present a good case for the dynamic estimates as more appropriate measures of historical variability. They go on to argue that the fact that their model produces error bounds less than the dynamic historical estimates is indicative of the improvements in estimates due to careful structural modeling over a naive extrapolation of trends. If we accepted this interpretation it would indicate that we actually did worse by having an even more detailed structural model. However, we are inclined to argue instead that Nordhaus and Yohe's assertation rests on fairly thin ice. As they note, any comparison between the projected and historical variation (based on the dynamic estimates) rests on the assumption that "the pace of economic structural change over the next 100 years is about as rapid as that over the last 100 years." Thus, one really has no reason to be confident that one can get a particularly good future prediction of a
best guess value or the variability of a value from a naive extrapolation model. Nevertheless, comparison to historical data offers one of the few validation alternatives available. Thus, estimates in this study are not particularly out of line with historical estimates. However, they do suggest somewhat greater variability than do Nordhaus and Yohe's estimates.
A major reason for greater variability in carbon emissions is probably a result of our different data set. Among the most important variables in explaining variation in carbon emissions in both our and N-Y's model is productivity growth. Because we disaggregate to two regions while Nordhaus and Yohe have a single region, the data sets themselves are difficult to compare but a direct comparison between global GNP is possible (see Table 12).
This greater variability in global GNP stems from our assumptions of considerably greater bounds on labor productivity growth. Our data set allows the possibility of economic stagnation and even slight decline. Combinations of global financial collapse, trade protectionism, political unrest, environment and resource stresses, and an inability to understand and correct the current productivity slowdown in the U.S. and other developed countries seem reason enough to allow for the possibility of stagnation even over a fairly long period.
At the other extreme, we also allow the possibility that economic expansion could be more rapid than Nordhaus and Yohe's highest rates. Some interpretations of the historical record would see a spiraling upwards of the rate of improvement over the long term; the 1960s showed record prosperity, with the 1970s showing a recession from those highs, to be followed by periods of at least as rapid or possibly more rapid expansion. Advances in computers and robotics might lead the way.
The comparison in assumed productivity growth rates is given in Table 13. But as noted earlier caution is needed in interpreting these figures (e.g., in our analysis a low rate for the developing regions is likely to be chosen in combination with an average or even high rate for the developed region). Thus our global productivity limits will be considerably tighter than the regional rates. But as can be seen from Table 12 the assumptions of no correlation between the two regions leaves the coefficient of variation in our study considerably higher than in the Nordhaus and Yohe study.
In contrast to our subjective determination of uncertainty trends for inputs, Nordhaus and Yohe use an analysis of published future estimates to develop their distributions. While the estimates they cite include estimates of high, mid, and low growth, there is no particular reason to believe that the range of estimates provides a range of the possible or even reflect the authors' beliefs of 90 or 95 percentile trends. In our view, the available literature estimates for future productivity growth all appear to be very middle-of-the-road, thus for labor productivity in particular, a resort to statistical analysis of largely best guess estimates appears to misrepresent the spread of the distribution as one might expect. Nordhaus and Yohe assumed that the estimates they had reflected random draws from the population. They might have assumed instead that each estimate was the mean of a random sample from the underlying population, and then applying theorems on the distribution of the mean:
_ _ ó2
E(X) = µ and VAR (X) = ----
n
__
where X is the random variable of the sample of estimates, µ is the underlying population mean, ó2 the population variance, and n the number of observations. To indicate the impact, Nordhaus and Yohe report estimates by 4 different organizations for productivity growth from 1975-2000. Using only the mid-estimate or the middle of the range (in cases where only a high or low estimate is given), the estimated mean and standard deviation for the population using the above formula is:
Nordhaus/Yohe Recalculated µ 2.3% 2.3% ó .7 1.1
Thus, while the mean remains unchanged, as might be expected, the standard deviation increases. While we set our distributions quite independent of this "evidence," the standard deviation for the distributions we set are 1.0 percent (developed region) and 1.6 percent (developing regions) with the coefficient of variation being 62.5 and 64.2. Thus, our distributions appear to reflect very closely the reinterpretation of the Nordhaus and Yohe data. Because the data is so sparse for periods beyond 2000, we do not attempt any comparable calculations.
CO2 trajectories
The previous figures, while useful, do not give an indication of the trajectories of CO2 emissions in individual scenarios. Trajectories of Individual scenarios can give some additional information about the time path of scenarios generated by the model. For example, a standard technique in the area has been to use a single equation with the recoverable pool of carbon as a primary variable. A logistics curve or some variant is typical. The general pattern sketched is a rising level of carbon use, a peak, and then a gradual drop off in emissions. Reister and Rotty (1983) have demonstrated that under suitable assumptions a more complicated model based on economic principles could generate such a scenario. The percentile plots do not indicate a peaking on average but individual scenarios do show peaks. The plots in Figures 10a-c represent all scenarios which show year to year declines after 2000. (The plots are based on the zero correlation Monte Carlo run.)
In total, 91 scenarios (or 23 percent of the 400) fall into this category. Of these, 71 show a longer term declining trend; plus, an
additional 62 scenarios (16 percent) show a decline in 2000 from 1975 and are below 1975 emissions in 2075. Thus, 33 percent of the scenarios show a peaking phenomenon. As some of the plots indicate, however, recovery of carbon emissions after a temporary decline is a possibility. It is also interesting to contrast these scenarios with similar plots of the Nordhaus/Yohe results. One criticism of their results is the implausibly rapid decline in emissions over very short periods, implying fuel switching or conservation efforts of truly massive proportions in a period of 25 years. (Reilly and Edmonds, 1985). The declines in Figure 10 are generally much less than those exhibited in the Nordhaus/Yohe study. Only a few of the scenarios show more than a halving of emissions over 25 years, with the most severe drop being a 4-fold decline. In contrast, some of the scenarios in the Nordhaus-Yohe study show a 20-fold decrease in 25 years. These differing results are indicative of the impact of different model structures.
Figures 11a-d are included to help develop an understanding of the forces leading to emissions peaks in different years. Figure 11a compares summary statistics for data assumptions in declining emissions scenarios to the general population of data assumptions. In so doing it becomes possible to identify those assumptions which are at variance with the general data input population. Data assumptions whose means and distributions leave them either significantly higher or lower than the general population means are inferred to be important.
It is interesting though not entirely surprising to see the changing importance of various factors over time. The sample of scenarios, which show declines from 1975 levels through to 2075 have significantly lower
labor productivity growth in developed and developing countries (PARM 31, 53) and have rapid technological progress in energy use efficiencies (PARM 12). Technological progress in coal mining is slower and resources somewhat lower (PARMs 60 and 54-58), both leading to higher cost coal. Biomass costs (PARM 2) are also lower and the income elasticity of energy use in the developing countries is significantly lower, though insignificantly different in other regions. The marginal significance of the E/GNP feedback elasticity in developed regions (PARM 4) is somewhat difficult to explain since its importance is linked to energy prices. A high (negative) value as indicated in Figure 1la would tend to reduce emissions if energy prices were rising rapidly.
In those scenarios that increase from 1975 to 2000 and then decline, a different set of parameters appears to be important. End-use energy efficiency (PARM 12) is important again but labor productivity is not. Additional parameters which are significantly different are the price demand elasticity (PARM 11), the gas and shale oil supply price elasticities (PARMs 53 and 67) and the nonfuel cost of synfuels (PARM 77). This suggests that the ability to expand production to make up for declining high grade oil resources is critical. Many of the scenarios in Figure 10a show a recovery in emissions after 2025. This is consistent with difficulty in bringing on sufficient capacity in other carbon fuels. While not significantly different at the .05 level, nuclear costs (PARMs 73 & 74) tend to be low in the sample.
The scenarios showing peaks in 2025 are characterized by high labor productivity in developing regions (PARM 32), low oil resources in the OECD (PARM 34-38), expensive coal (PARM 59, 60), and rapid technological
progress in nuclear (PARM 74) but high environmental costs associated with nuclear. The E/GNP feedback elasticity in the developing regions is also important. The relatively high cost of coal is not surprising. The apparently conflicting signals on nuclear energy would seem to result from the particular model formulation. The environmental costs are specified as an add-on cost gradually phased in while technological progress is an exponential growth factor. The particulars of the data and model formulation would probably tend to produce a peaking (or at least a rapid rise followed by a slower rise) of nuclear prices with the combination suggested by Figure 8c. There is not an obvious reason for high labor productivity growth in the developing regions to be associated with a peaking in 2025. This apparent correlation may be coincidental.
Finally, those scenarios which peak in 2050 show high labor productivity growth but also show low shale oil resources (PARM 63-66) and high nuclear resources (PARM 70-72) as well as high cost coal supply (PARM 59, 60). This pattern of resource constraints and rapid economic growth causing an emissions peak is consistent with the simple emissions peak models. However, conventional defined "resource" factors do not necessarily come into play. In setting up the data, the lower end of the distributions for higher grade shale resources are set at or near zero to include the uncertainty surrounding the technology as well as the resources. That is, there is uncertainty about how much 50 gal/ton shale exists but also whether the 50 gal/ton shale can be produced at $20, $50, or $200/barrel. Thus, the fact that the shale resources PARM plays a role should probably be interpreted as indicating that very little of the resource is producible under most prices rather than that known shale resources are being exhausted.
The significance of different factors should also be considered in light of the still wide range of scenarios left in the subsamples. In particular, the subsample showing peaks in 2050 could probably be grouped further to show clearer trends. For example, many of the very low scenarios may be more similar to the group of scenarios which shows decline from 1975 (e.g., low productivity growth, slow technological change in fossil fuel production), while the high scenarios may peak due to exhaustion of high grade coal resources even though for the full subsample of 2050 peaking scenarios, coal resources are not significantly higher.
Importance of Input Assumptions
The relationships between model predictions and parameters can be analyzed by regression based techniques. The importance of a particular parameter is a function of its sensitivity, variance and interactions with other model parameters. Thus, the Monte Carlo analysis reflects a combination of model and data characteristics while a sensitivity analysis reflects only the model characteristics since changes in parameter values are small and equal.
Parameters explaining uncertainty in carbon emissions. Figure 12 shows the four parameters which explain a significant portion of the variability in carbon emissions in the 400 scenarios; they are labor productivity in developed regions and in developing regions, exogenous energy efficiency, and the income elasticity of demand for energy in developing regions. The figure is based on log transformed data since it provided a better fit (as indicated by the R2). Ranking of variables remained unchanged among the most important variables between the
nontransformed and log transformed data. The main conclusion that can be drawn from Figure 12 is that a significant reduction in the spread of the output would require additional resolution in some or all of these four variables, particularly labor productivity.
Beyond this summary conclusion, it is useful to examine the results in detail since they provide additional insights into the model. Table 14 contrasts the ranking of parameters in the sensitivity and uncertainty analysis. These results are based on the data output from the uncorrelated case since the correlations among parameters introduces obvious bias in estimates.
Examination of the relative partial sums of squares in the Monte Carlo ranking shows the fairly clear dominance of the four parameters graphed in Figure 12. For the most part, the parameters break down into 3 groups: the four important parameters; four (five) additional parameters which rank among the top 10, including biomass cost, environmental cost of coal in developing countries, income elasticity in the OECD, the aggregate price elasticity of demand, and technological change in coal production (which ranks in all years but 2000); and the remaining set of parameters which never rank or rank only for a year or two.
The sensitivity ranking shows somewhat different results; the top group of parameters in terms of sensitivity consists of only two, the income elasticity and labor productivity growth, both in the developing countries. These are followed by a second group of parameters which tend to exhibit relative partial sums of squares from .05 to .15. These include labor productivity in developed countries, exogenous energy efficiency, population parameters and the income elasticity in the OECD.
The biggest difference between the rankings is the disappearance of population from the Monte Carlo rankings. This difference is explainable as due to the relative narrow distributions for population.
Comparison to Nordhaus and Yohe's ranking. Nordhaus and Yohe (N-Y) conducted a very similar analysis and ranking of parameters. While the ranking of parameters tend to be difficult to compare because parameters are defined differently, some comparisons can be made. First, labor productivity in the developing regions is a clear first in this study, with productivity in developed regions third or fourth. N-Y has a single world region. Thus, one might expect productivity to rank a clear first. It ranks second and two factors appear likely to lead to this result. First, this study has a considerably broader distribution on labor productivity. (This is discussed in detail in a later section--pp. 64-69.) Second, the N-Y model formulation implicitly aggregates labor and energy productivity growth in the labor productivity parameter. Energy productivity is similar in concept to exogenous efficiency (PARM 12). The impact of combining these two concepts in one parameter is equivalent to assuming perfect correlation between them. Since greater labor productivity alone would tend to increase output and energy demand (and CO2 emissions) while improved energy productivity would tend to reduce energy demand (and CO2 emissions), perfect correlation between these would clearly narrow the distribution from the no correlation case.
The parameter that ranks first in the N-Y study is the price induced substitution parameter. Here the model specifications are actually quite similar in most regards and in addition the Monte Carlo analysis in this study is conducted such that perfect correlation among regional values of
the parameter is assumed thus making it identical, for Monte Carlo analysis purposes, to assuming a single world region. These similarities make it surprising that the substitution parameter (PARM 3) does not rank at all in any year. The major reason for this result is probably the fact that in the IEA/ORAU model four secondary fuels exist (electricity, gases, liquids, and solids). In contrast, in the N-Y study there are two fuels, fossil and nonfossil. Suppose the price of fossil energy rises in the N-Y model. Obviously the ability to substitute to nonfossil energy (as represented by elasticity) will significantly affect carbon emissions. If substitution is very easy demand will fall greatly for fossil and rise for nonfossil. If substitution is difficult a considerably smaller change in fossil use will occur. Of course, reductions in output (GNP) will somewhat counter these direct effects but it is not surprising that the substitution effects significantly outweigh the output effects.
Now suppose the price of a fossil fuel (e.g., coal) increases in the IEA/ORAU model. First, this shifts the mix of solids towards biomass before the fuel substitutions demand elasticity can have any impact. Next, consumers respond by switching to fuels other than solids; i.e., liquids, gases, or electricity. But even if end-use consumers switch completely out of solids the impact on carbon emissions is indeterminate. They could switch to liquids which might be shale oil or coal liquids which would increase carbon emissions or might be biomass liquids which would decrease emissions. Consumers might also switch to gas but for similar reasons as for oil, this switch could increase or decrease emissions. Similarly, electricity is generated by both fossil and nonfossil sources. Of course, the rise in coal prices would tend to reduce the average emissions ratio
per unit of electricity but this ratio might still be higher than direct use of solids. Thus, since it is likely that the average emissions rate for end-use fuels are not that different it is not surprising that whether fuel substitutability is easy or not makes little difference.
Presumably it would make a difference in our model if all fossil fuel prices were strongly correlated and if all nonfossil fuel prices were strongly correlated but fossil and nonfossil were uncorrelated. This would essentially be the N-Y assumption of two fuels. If fossil fuel was the paradigmatic exhaustible fuel and nonfossil is the inexhaustible fuel, this might lead to the necessary set of correlations. The IEA/ORAU model, by including exhaustion explicitly, provides a test of the importance of exhaustion in generating such correlation and, as is obvious by the findings, the test is negative.
The conclusion is that the N-Y findings of the importance of the substitution parameter is clearly a finding idiosyncratic to the insufficiently general model structure; i.e., the model enforces an implicit assumption of perfect correlation among fossil fuels and among nonfossil fuels thus any change in relative prices necessarily induces an unrealistic choice between a high CO2 emitting fuel and a fuel which emits no CO2.
The other parameter which is important in this study is the income elasticity of energy demand in developing countries and less so for other regions. The N-Y model does not include a comparable concept. In the N-Y production function formulation an income elasticity would be similar to a return to scale parameter; by omission, it is implicitly constant at unity.
Another relatively important parameter in the N-Y results is the labor-energy tradeoff. This is very similar to the IEA/ORAU aggregate energy elasticity parameter (PARM 11). While PARM 11 ranks, the relative partial sum of squares is fairly small and is clearly less important than in the N-Y study. This is probably a result of the relative nature of the measures of importance rather than an absolute difference. Since this study gives a broader range of uncertainty to labor productivity all other parameters become relatively less important. Similarly the income elasticity is a significant source of variability in this study but is omitted from the N-Y study thus reducing the relative importance of other parameters in this study.
Beyond the parameters listed above, the disaggregation of the IEA/ORAU model versus the highly aggregated nature of the N-Y motel makes comparisons impossible given the analyses of results to date. Further analysis of this study's set of output data, i.e., computing relative partial sum of squares for groups of parameters, could shed additional insight on relative rankings. For example, the relative partial sum of squares could be computed for the group of all parameters connected with fossil resources, non-resource cost factors or nonfossil fuel prices, thus providing groups similar to the aggregate concepts in the N-Y study.
The importance of parameters for outputs other than emissions. The importance of input assumptions depends on the output value of interest. Table 15 gives the R2 value for each year for both the log transformed and nontransformed data. As noted previously, the log transformed data give a higher R2, thus the model is more nearly log linear than linear in CO2 emissions. However, even in the log linear specification 15 to 25 percent of the total variability remains unexplained when all parameters contributing to variability are included. Thus, there are significant nonlinearities in the model and the possibility exists that the ranking of
parameters would be affected if some act in a particularly nonlinear fashion on carbon emissions. On the other hand, the fact that rankings did not change much when moving from the linear to log-linear specification is reassuring. In addition, the big gap in relative partial sums of squares between the top four parameters and the next group makes it unlikely that an unranked parameter could move in to the top group of parameters.
The last two columns of Table 15 indicate the R2 for the sensitivity analysis data. Given the relatively small variation in parameters (2 percent) nonlinearities are expected to be less important (i.e., a linear function can provide a relatively good fit over a short portion of a curved surface). This expectation is borne out by the results.
Table 16 reports the R2 value for primary energy, final GNP, and the oil prices for the linear and log transformed data. The R2 value for these outputs are very similar to those for CO2 emissions and similar conclusions can be drawn.
Regression analysis of additional output variables. Table 17 provides a sketch of the ranking of variables important in explaining variability in output for other model outputs (VALs). It also provides the R2 for each regression. Rather than go through these results in detail, only a few remarks will be made. It is of interest, though probably not surprising, that labor productivity (PARMs 31 and 32) rank for nearly all outputs and PARM 32 frequently ranks 1 or 2. Another noticeable pattern is that PARMs 32 and 9 (both associated with developing countries) typically rank higher than their developed country counterparts (PARMs 31 and 7) and tend to increase in importance over time. Also noticeable is the absence of resource constraints. While resource constraints in oil and gas definitely affect results, apparently existing uncertainties in resource availabilities are not enough to create a significant amount of uncertainty in most output measures when compared to other assumptions. However, this conclusion must contain a strong caveat given the low R2 for oil and gas production.
Not surprisingly, parameters which are fairly obviously connected to individual outputs appear important; e.g., solar cost (PARM 75) and solar production, nuclear costs (PARMs 73, 74) and nuclear production, biomass cost (PARM 2) and biomass production. In general, there are no unexplainable results in Table 17, confirming that the model reacts as one would expect.
Analysis of Energy Results
The IEA/ORAU model is relatively detailed, yielding numerous results incidental to the projection of carbon emissions. This section briefly reports characteristics of distributions of selected outputs. Additional detail and characteristics of other outputs are contained in Appendix D.
Aggregate energy. Figure 16a shows the 5th, 50th, and 95th percentile values for global primary energy consumption. The median case shows a 1.7 percent per year increase from 1975 to 2075 but the 90 percent confidence limits are fairly broad. It is worth noting that even the 95th percentile value (which represents an average growth of 3.7 percent per year through 2075) is considerably slower than the 4.5 percent per year increase in energy consumption over the period 1955 to 1975 and is only slightly faster than the 3.3 percent per year increase for the 56 years between 1925 and 1981. In fact, the projections suggest only a 10 percent probability that energy use over the next 100 years will grow as rapidly as it did over the past 55 years. The median growth value represents just slightly more rapid growth than the 1.5 per year growth registered between 1973 and 1981.
Energy prices. Figure 16b gives 5th, 50th, and 95th percentile values for world oil prices. The distribution is somewhat surprising in that
there is very little spread until after 2025 and the 95th percentile for 2000 is well below the peak in oil prices in 1980. This seems clearly at odds with conventional wisdom. Even with the current (1984-85) oil glut and significant declines in prices, both in nominal and real terms, since 1980, the conventional wisdom can probably be characterized as holding that moderate rises in oil prices could be expected by 2000 ($40-$50 per barrel oil, 1985 dollars) with a significant chance that tightening markets could make possible larger increases if combined with political disruption in the Middle East or allow OPEC to assert oligopolistic control over prices. Such scenarios are dependent on limited foresight, inability to substitute away from oil in the short term, and possibly panic buying to build up stocks. While we have included a fairly high probability of small amounts of high grade resources in the Middle East to represent the possibility of using market power to make known oil available only at higher cost, the model does not distinguish short- and long-term demand elasticities. Moreover, the model includes no mechanism to represent a supply disruption and rising prices which temporarily increase demand (due to stock building) thereby feeding a price spiral, as buyers panic on expectations that supplies may be cut even further.
It is probably the case that the distribution of prices for 2000 under-represents uncertainty, suggesting too little probability of high oil prices. However, the protections suggest that, based on long-term factors, such increases would be hard to maintain. Thus, the results should probably affect expectations. Further, in thinking about a reasonable set of expectations one needs to consider the probability of disruption scenario over, for example, the next 25 years and how long a price run-up
can be maintained in the face of long-term factors suggesting lower prices; e.g., a 50 percent chance of a major disruption within the next 25 years leading to a tripling of prices, with high prices maintained for 2 years, translates into only a 4 percent chance that prices would be triple their current value in any one year. Varying the probabilities can give different results, but the point of the example is to show that even a relatively high probability of disruption can translate into a relatively small effect on price projections for a given year.
More basic issues remain unexamined in the effort as they do in most projections and analyses. In particular, the psychology of producers and consumers changing supply and demand conditions and prices. Panic buying, stock building under high prices, desires for stability, cooperative and competitive behavior among producers, are observed but currently not explained in ways which can be introduced easily into predictive models.
Beyond 2025 the distribution broadens rapidly. This is apparently due to the exhaustion of most high grade conventional oil and uncertainty concerning the price at which alternative fuels could be available. If coal and biomass conversion processes are inefficient and require larger capital investment and coal and shale oil are expensive due to environmental and technological considerations, tremendous pressure on oil prices could exist. On the other hand, if oil demand is low or other liquids are available at low cost, prices rise only modestly from current levels.
It is also interesting to note the significant impact the correlated inputs case has on the 95th percentile. The specific assumption with the most direct impact on prices is the correlation between labor productivity
growth and technological progress in production and use of energy. Thus, in high GNP cases, demand is lower due to efficiency improvements in energy use and supply is higher due to technological improvements in production. These combined effects have an a priori indeterminate impact on fuel consumption but have a clear negative impact on prices.
Fuel production. Figure 17 shows the 5th, 50th, and 95th percentile values for oil (excluding shale oil), gas, coal, nuclear, solar electric, biomass, and shale oil production. Conventional oil and gas production both show a tendency to peak and decline. Again, care must be used in interpreting the percentile plots; i.e., it is unlikely that any of the scenarios show as much cumulative production as represented by the area under the 95th percentile plot. Instead it probably represents the highest points of high scenarios which peak in different years. Also, note that data for oil resources include significant amounts of resources above $70/barrel (1985 U.S. dollars) or $7 gigajoule (l975 U.S. dollars) including such resources as tar sands, heavy oil, oil from deep oceans and polar regions, etc. Since oil prices go above $7/GJ in only 25 to 30 percent of the scenarios these resources are not exploited in many cases. Gas resources are treated similarly and high cost gas is potentially a huge resource but gas prices do not rise even as high as oil prices and therefore the existence of these huge gas resources does not prevent a peaking tendency in gas production.
Among the remaining fuels there are very similar patterns. There are a few very high scenarios but 50 percentile values are relatively low. This represents significant variability in projected fuel consumption. This variability is also reflected in the coefficient of variation shown in
Table 18 for 2075. It is interesting to observe that the tendency toward exhaustion of oil and gas leads to relatively lower variability for these fuels compared to primary energy and to other fuels. Not surprisingly the fuels not currently in wide use--shale oil and solar electricity--show the greatest variability.
Among the fuels, the results for shale oil are somewhat puzzling. Whereas other fuels have some scenarios where several hundred exajoules are produced, the 95th percentile for shale oil is less than 30 exajoules. This seems unreasonably low. This result appears to be related to the way production startup is handled in the model. As is discussed in Appendix B, energy production has two constraints on production, the resource base and short-term capacity expansion constraints. For shale oil the resource base appears never to be a constraint. Production is constrained solely by the short-term capacity expansion mechanism in the model. For fuels with no
production in period t-l, a relatively low start-up quantity is assumed to be produced in year t. For fuels having production in period t-l, production in t-l forms the base production. Thus for oil, gas and coal relatively large base quantities are used relative to total energy energy production. But any scenario including shale oil must start from the very low production base. This low base combined with the low variability in price (very high scenarios are uncommon due to the alternative source of abundant liquids, synoil from solids), and supply elasticities, result in a relatively tight connection between overall economic activity and shale oil production in later years. While difficulty in expanding shale oil production may be likely, it would seem that under some proportion of scenarios shale oil production could reach 100 or more exajoules. Thus, this part of the model/data should probably be examined and reformulated.
CONCLUSIONS
Over the last 15 years researchers have changed greatly both their expectations about future levels of CO2 emissions and the way in which they conceive of emissions futures. Early studies used time trend analysis to generate a single "best guess" scenario and obtained future CO2 emissions growth rates of 4.5 percent per year. By 1982 the consensus had shifted. Clark (1982) cites more numerous and more sophisticated studies and a consensus value of 2 percent. But the mode of analysis remained the same, scenario analysis.
In 1983 Nordhaus and Yohe addressed the problem for the National Research Council. In their work they broke from the use of scenario analysis introducing an alternative methodology which they termed
"probabilistic scenario analysis." Their approach addressed the uncertainty explicitly and quantitatively. A median probability scenario replaced the "best guess" scenario which was in turn bracketed by confidence intervals. Their analysis put the most likely rate of carbon emissions growth at a still lower 1.2 percent per year and constructed 90 percent confidence bounds on the annual rate of between 0.3 and 2.0 percent.
This study follows suit by employing quantitative uncertainty analysis in conjunction with a more detailed model of global energy and CO2 emissions. The result of our research is to lower still further the median growth rate of global CO2 emissions to between 1.0 percent per year (zero input cross correlations) and 0.5 percent per year (nonzero input cross correlations). At the same time it widens the difference between the 90 percent confidence intervals to between 3.0 and -1.4 percent per year for the zero cross correlated case (somewhat tighter for the correlated case). This study therefore indicates that CO2 emissions are likely to grow, but that the possibility of a dramatic buildup of atmospheric CO2 from fossil fuel emissions is smaller than previously thought. While some of the 400 scenarios generated were associated with growth rates in CO2 emissions of 4.5 percent per year or more, such a high growth rate appears highly improbable.
The use of Monte Carlo analysis in conjunction with a detailed model of the global energy system is extremely important. It leads to very different results than "best guess" analysis, even in conjunction with a sensitivity analysis. CO2 emissions reach 21 gigatonnes per year in 2075 when median input assumptions are used. In contrast the median rate of CO2
emissions is 13 gigatonnes (8 in the nonzero cross correlation case) when the entire range of input uncertainty is included using Monte Carlo techniques. This extraordinary difference (60 percent in the zero cross correlation case and 160 percent in the nonzero correlation case) argues for the value of addressing uncertainty explicitly.
A large number of scenarios were generated in the analysis. Statistical techniques were then applied to reveal more clearly model-data relationships over the range of data input uncertainty (as currently perceived). The first result worth noting is that model structure is extremely important in determining model results. The extraordinary difference between model inputs evaluated at median input values and the median of model outputs for CO2 emissions makes the point eloquently. Furthermore, the striking difference in results between cross correlated and uncorrelated input assumptions leads us to conclude that results can be highly dependent on the model's exact form. Changing the model input relationships is equivalent to altering the model. Where major inputs (as measured by sensitivity and uncertainty analysis) are concerned, respecification can have a powerful influence on results.
Second, in addition to model structure, three variables play dominant roles in determining CO2 emissions:
Other important factors include:
Conspicuously absent from the list is the rate of interfuel substitution which Nordhaus and Yohe found to be the most important determinant of CO2 emissions. Similarly, resource constraints on energy were not significant, despite the fact that the model structure explicitly allows that possibility. And while approximately one-quarter of all scenarios were characterized by a peak in CO2 emissions followed by a decline, preliminary analysis indicates that resources played only a minor role in the phenomenon. Logistics curve like models are therefore a poor choice to use as a reduced form representation of the more complicated energy system structure.
The conduct of a Monte Carlo uncertainty analysis in conjunction with an analysis of model-data interactions comes at an important point in time. Keepin and Wynne (1984) have argued strongly for the need to conduct a rigorous analysis of forecasting tools used in the energy field, and the need to test the robustness and sensitivity of results. They argue strongly for an open and accessible documentation and rigorous peer review. This report is a first step in that direction.
NOTES
Energy-economic models, and especially the behavioral subset of this genre, work out the consequences of assumptions. Their question is essentially what will happen as opposed to can an event happen.
But these approaches are not so different as they might appear. Both have in common a detailed structural framework of analysis which incorporates causal factors such as population, economic growth and development, technology, geology, and sociology, in meaningful ways. Furthermore, because of the nature of the analytical process, both spend most of their efforts working from assumptions to conclusions. This is the nature of a behavioral model. But feasibility studies are irrelevant outside of context. They need an underpinning of constraints to reduce the number of free variables to a manageable number. Feasibility studies therefore work within the context of assumptions about available technologies to determine whether or not a constraint, in this case fossil fuel CO2 emissions, can be met.
In contrast, Nordhaus (1979) uses a computer-based linear programming model which requires the specification of a great wealth of information about technologies, both those employed and alternative options available. The model is computer-based and employs an optimization criteria to generate an optimum solution. It is capable of being used as both a forecast tool (by using a maximization of global GNP and assuming that the global economy behaves "as if" it optimized this value) or as a feasibility tool (by placing CO2 emissions constraints on the outputs).
Haefele (1981) documents a complex set of models including linear programming, accounting, and input-output models. The system is resident on a computer but is extremely complex. The Edmonds-Reilly model (1983) is a behavioral market equilibrium model which balances energy production and use internally. It is discussed in detail in section 3.
The first category contained only resources producible at 1975 prices. A time path of production was specified and prices were allowed to vary so that demand equaled the fixed supply. As prices increased beyond a minimum break-through price, the supply of exhaustible fossil fuels was augmented by unconventional sources of liquids and gases.
This approach proved to be somewhat cumbersome in some scenarios. Specifically, in very low demand scenarios prices could drop well below 1975 levels; to maintain consistency the user would have to exogenously respecify a lower resource. In addition, the supply of unconventional liquids and gases required a base quantity for each period. This base quantity was exogenously entered. This approach also required user interaction to assure that the producing sector behaved sensibly; i.e., that producers adjusted expansion plans for the next period to reflect the realized rate of production in the current period.
For a full description of the original model see Edmonds and Reilly (1984). The relationship between the original and current model versions is documented completely in Appendix B.
A second problem is that any description of uncertainty based on statistical analysis is premised on the adequacy of the structural model and the data set used to make the estimate. In the population example above, we described two possible data sets, time series or
cross sectional data. The two will give different estimates of mean and variance, thus exposing structural uncertainty that would not be incorporated in a statistical analysts which uses only one of the data sets. Similarly, estimates of parameters such as the price elasticity of demand are dependent on the specific equation estimated.
One approach for retaining an objective methodology for estimating uncertainty in inputs is to use statistical analysis of published estimates. Such an exercise suffers from a couple of severe problems. First, published estimates are generally best guess estimates. While a sample of best guess estimates can, under appropriate conditions, yield an unbiased estimate of the mean of a distribution, it will not yield an unbiasd estimate of the variance. A second problem is that different concepts of parameters may exist, some more or less applicable to the specific parameterization in the model.
For example, price elasticities may be estimated for primary, secondary, or energy service demands (though data is usually not available for estimation of service demands) and estimates may be based on various aggregations of consuming sectors (e.g., the economy as a whole, the industrial sector, SIC industrial categories, etc.). Since price elasticities are, in principle, specific to the category of demand being analyzed, a specific price elasticity estimate may be more or less relevant to the parameter assignment in the model. An even simpler example is that GNP growth protections from published estimates are given for dissimiliar regional aggregations and may be premised on considerably different population and labor force growth estimates; further, they may or may not include feedback from various assumptions about rising energy prices. Some incomparabilities represent legitimate sources of uncertainty in the parameter while others are merely artifacts of definitional differences.
As a result of the various problems discussed above, the approach chosen for developing the data base of input parameters was to critically review the literature and assign a subjective, but quantitative, description of uncertainty to each parameter. The adequacy of the parameterization of uncertainty is dependent on the understanding of the "quality" of different published estimates for use in the particular model structure and Monte Carlo exercise (i.e., "quality" in the sense of how comparable the published parameters are to the specific model parameterization).
Once it was determined that the model could in fact be successfully solved at extreme values for input assumptions, the Monte Carlo computer code, PRISM was tested by varying each of the 79 Monte Carlo variables +/-2 percent. This exercise produced quantitative results on the responsiveness of the model to small derivations from median input values. These were directly comparable to earlier calculations in Edmonds et al. (1984) and provided verification of the successful linkage of the Edmonds-Reilly model fo PRISM.
Initial attempts to conduct the Monte Carlo analysis resulted in an 8 percent rate of failure to reach solution. Failures were analyzed and corrective measures taken. About half of the failures to reach solution were the consequence of the interaction of extreme assumptions. The model was modified to account for such occurrences. The other half of the failures were idiosyncratic to the solution hmodel's mechanism. That is the model cannot be solved directly. Global energy prices consistent with global energy balance are found through a search procedure. In some cases the search procedure broke down. To address this problem alternative procedures were devised to find solutions in the event of breakdowns. These changes and some additional debugging of the link between the Monte Carlo code, PRISM, and the model, reduced the number of failures to one.
Forty-six Monte Carlo parameters are deterministically linked. Linked variables are listed below:
Listing of Linked Monte Carlo Parameters by
Parameter Number and Assumption description
Assumption Description Parameter Numbers
Population (years 1975-2100; OECD & USSR) 13,14,15,16,17,18 Population (years 1975-2100; China) 15,26,27,28,29,30 Conventional Oil Resource (Grades 1-5; OECD & USSR) 34,35,36,37,38 Conventional Oil Resource (Grades 1-5; LDC's) 39,40,41,42,43 Conventional Oil Resource (Grades 1-5; Mideast) 44,45,46,47,48 Natural Gas Resource (Grades 1-4) 49,50,51,52 Coal Resource (Grades 1-5) 54,55,56,57,58 Unconventional Oil (Grades 1-4) 63,64,65,66
REFERENCES
*U.S. GOVERNMENT PRINTING OFFICE: 1986-181-179:50092
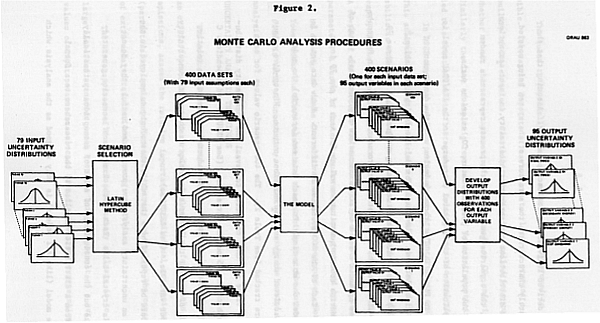{kind=link}
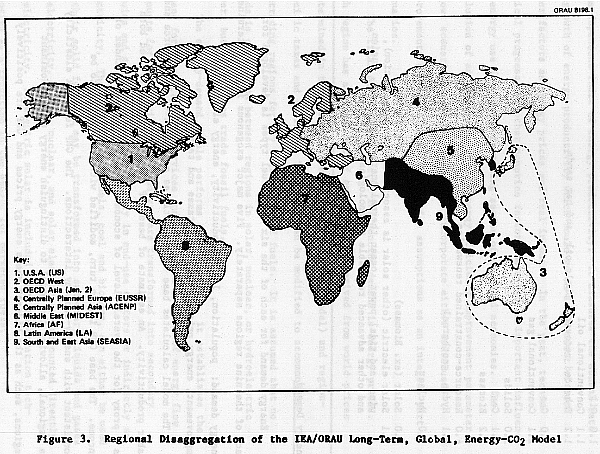{kind=link}
{kind=link}
{kind=link}
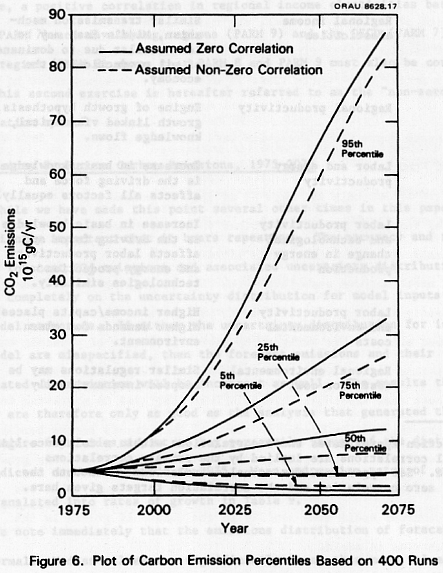{kind=link}
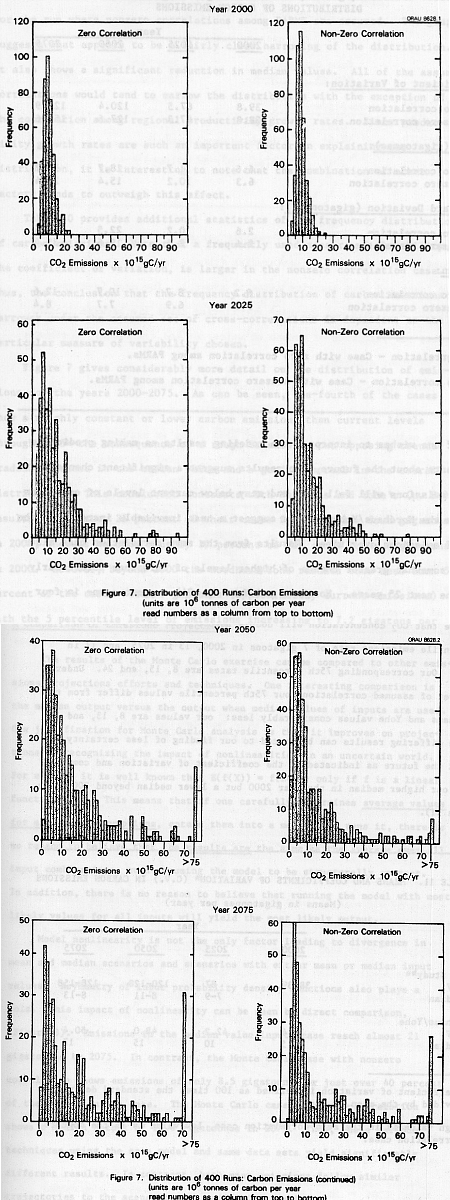{kind=link}
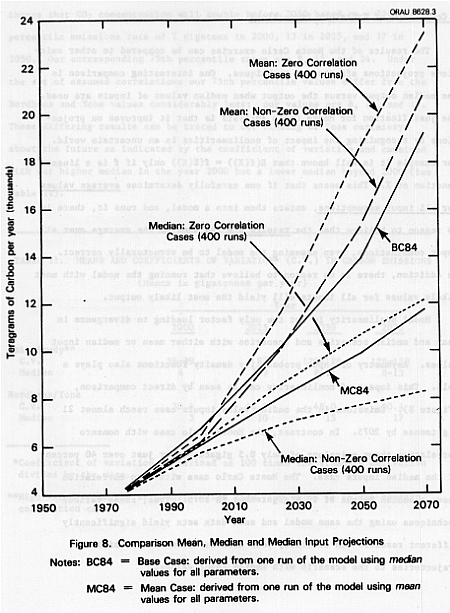{kind=link}
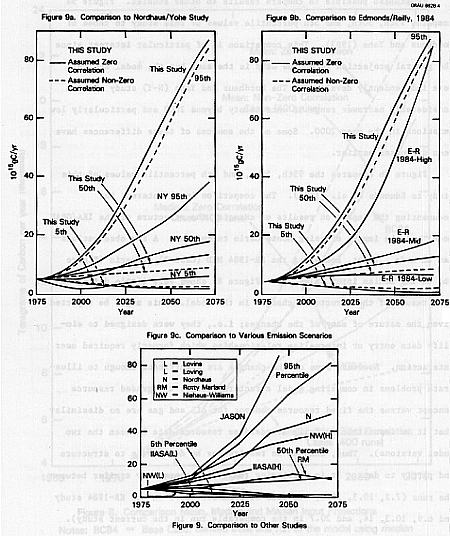{kind=link}
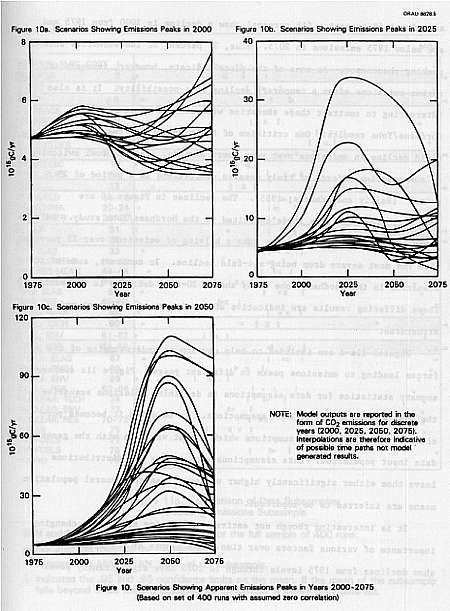{kind=link}
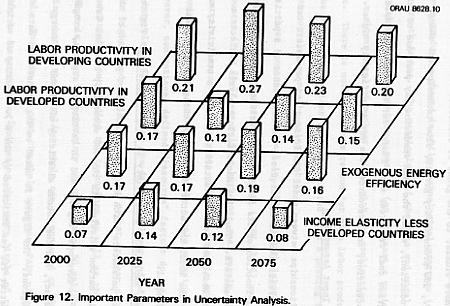{kind=link}
{kind=link}